

Table of Contents
Related to: Microsoft’s Agent Evaluation GA announcement on March 31, 2026, update to Testing Copilot Studio Agents: Copilot Studio Kit vs. Agent Evaluation (Preview)
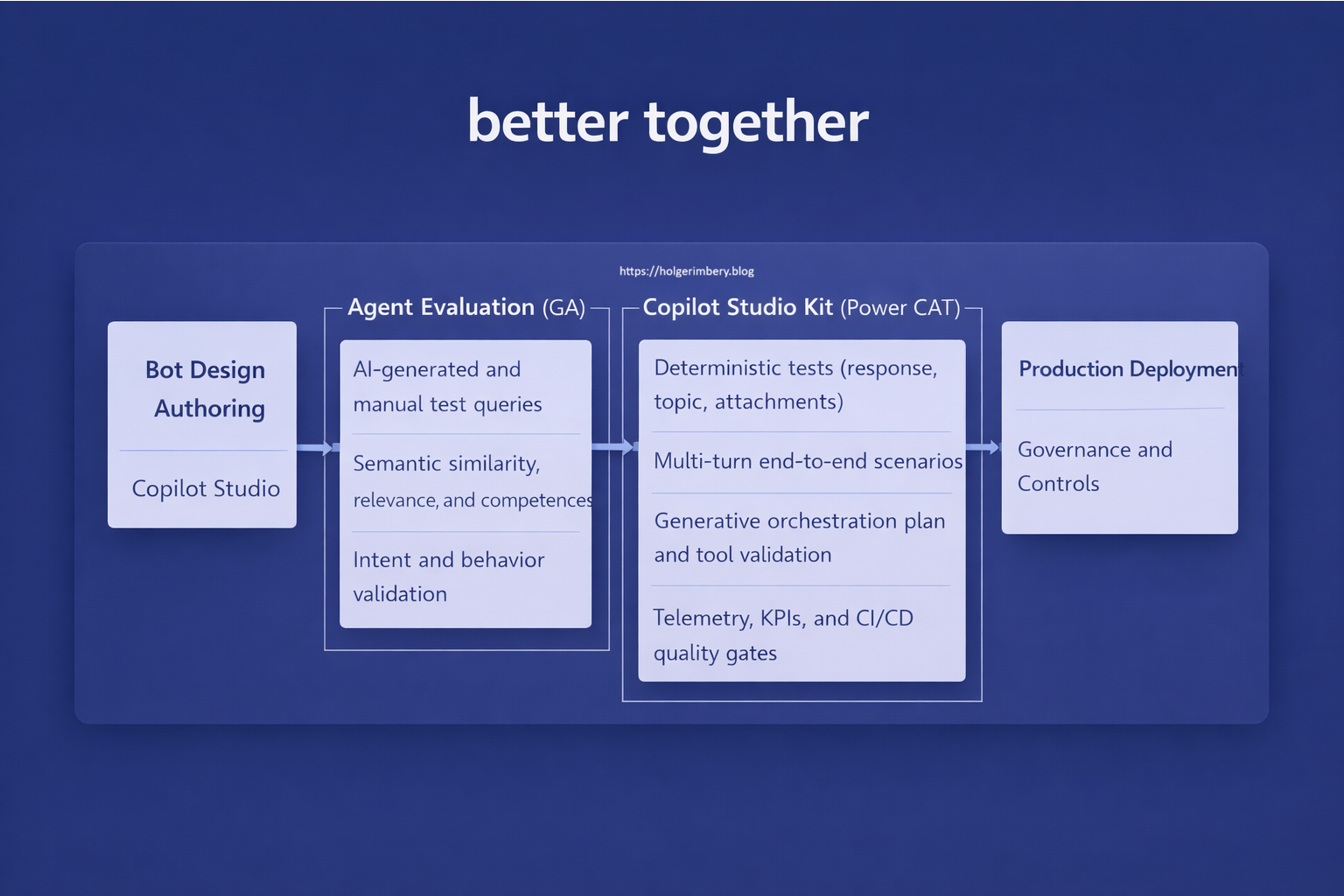
Summary Lede Agent Evaluation and the Copilot Studio Kit are not competing tools—they represent a layered quality-assurance strategy. Agent Evaluation provides fast, AI-assisted behavioral validation embedded directly in Copilot Studio, ideal for iteration and rapid feedback. The Copilot Studio Kit delivers deterministic, enterprise-grade verification for production gates, compliance, and governance. This article breaks down what each tool does, when to use them, and how to adopt both as your agent quality matures.
Why read this If you’re building or scaling Copilot agents in your organization, you need clarity on testing strategy. This article cuts through the positioning and provides a practical decision framework for when to reach for Agent Evaluation versus the Copilot Studio Kit, with real-world scenarios showing how mature teams layer both tools across their development lifecycle.
What Microsoft shipped with Agent Evaluation (GA)
On March 31, 2026, Microsoft announced the general availability of Agent Evaluation, marking a significant milestone in Copilot Studio’s testing and validation capabilities. Agent Evaluation is now generally available and built directly into Copilot Studio. Its goal is to make agent quality visible, repeatable, and scalable without requiring external tools or setup. This GA release represents the culmination of Microsoft’s efforts to democratize agent quality assurance, bringing evaluation capabilities previously limited to advanced setups directly into the hands of everyday agent makers in the Copilot Studio authoring environment.
Core characteristics (as of 31. March 2026)
Integrated directly into the Copilot Studio authoring experience Agent Evaluation is not a separate tool or external service. It lives within the Copilot Studio interface, where agents are built, allowing makers to validate their agents without context-switching or complex integrations. This tight integration reduces friction and encourages frequent validation during development cycles.
Designed to answer the production question: “Can we trust this agent to behave correctly, consistently, and safely?” This core question drives the entire design philosophy. Agent Evaluation focuses on behavioral confidence—whether the agent produces appropriate, consistent, and safe responses across diverse scenarios and user inputs.
Replaces unscalable manual testing and spot‑checking Before Agent Evaluation, agent validation relied heavily on manual testing: individually testing scenarios, reviewing responses, and hoping coverage was adequate. This approach doesn’t scale with agent complexity or usage volume. Agent Evaluation automates and scales this process through AI-assisted evaluation and reusable test sets.
Intended to be used before launch and continuously after changes Agent Evaluation is not a one-time gate. It’s designed for continuous validation: before initial launch, before deploying updates, and continuously as conversations flow through production. This shift from ceremonial testing to continuous validation aligns with modern DevOps practices.
Evaluation capabilities
Agent Evaluation allows makers to:
- Create evaluation sets from:
- Manually added questions
- Imported test sets
- AI‑generated queries derived from agent metadata and knowledge sources
-
Choose flexible evaluation methods, including:
- Exact/partial match
- Semantic similarity
- Intent recognition
- Relevance and completeness scoring
- Mix AI‑generated and human‑defined scenarios to balance breadth and depth
- Reuse evaluations over time and run them via APIs for lifecycle testing
Key framing: Agent Evaluation is positioned as a lightweight, AI‑assisted validation layer that fits naturally into everyday agent authoring and iteration. Unlike heavy external testing frameworks that require context switching and specialized infrastructure, Agent Evaluation operates within Copilot Studio itself, where agents are built. This embedded approach acknowledges that agent makers are iterating rapidly, testing comprehensively at each step, and need validation feedback within their authoring flow rather than as a post-production bottleneck. The AI-assisted scoring means makers don’t need to hand-write every test case or define complex rubrics upfront; they can generate relevant test scenarios from their agent’s own knowledge sources and metadata, then refine them. This makes evaluation accessible to makers of all skill levels and scales with agent complexity.
What the Copilot Studio Kit provides for testing
The Copilot Studio Kit (Power CAT) is a separate, solution‑based toolkit that augments Copilot Studio with enterprise‑grade testing, governance, and analytics. Developed by the Microsoft Power CAT (Patterns and Practices) team, the Kit represents a mature, production-ready framework built for organizations requiring rigorous quality assurance, regulatory compliance, and scalable CI/CD integration. While Agent Evaluation addresses everyday iteration and behavioral confidence within the authoring canvas, the Copilot Studio Kit provides the structural backbone for organizations that need deterministic verification, audit trails, multi-layer testing orchestration, and governance enforcement across large deployments.
Explicit testing capabilities
The Kit supports structured, deterministic, and multi‑layer testing, including:
- Response Match (exact or conditional text comparison)
- Attachment Match (Adaptive Cards/files)
- Topic Match (requires Dataverse enrichment)
- Generative Answer evaluation using AI Builder and rubrics
- Multi‑turn tests running in a shared conversation context
- Plan Validation for generative orchestration (verifying which tools/actions are invoked, not just what the agent says)
Execution and automation
- Tests are executed via Copilot Studio APIs (Direct Line)
- Bulk creation and maintenance via Excel import/export
- Detailed run‑level telemetry:
- Pass/fail
- Latency
- Observed responses
- Aggregated metrics
-
Results can be enriched with:
- Azure Application Insights
- Dataverse conversation transcripts
Enterprise extensions beyond testing
The Kit also includes:
- Conversation KPIs for Power BI
- Prompt Advisor
- Agent Inventory
- Agent Review Tool
- Compliance Hub with policy enforcement and SLA‑driven reviews
Key framing: The Copilot Studio Kit is built for verification, regression testing, production gates, and governance at scale. Unlike Agent Evaluation’s lightweight, AI-assisted approach that lives within the authoring canvas, the Kit functions as an enterprise testing backbone designed for organizations that require deterministic verification, full audit trails, and regulatory compliance enforcement. It bridges the gap between development-time validation and production-readiness, enabling structured quality gates that align with enterprise DevOps pipelines. The Kit’s emphasis on exact response matching, topic validation, and orchestration plan verification makes it essential for mission-critical deployments where agent behavior must be predictable, traceable, and compliant.
Direct comparison
| Dimension | Agent Evaluation (GA) | Copilot Studio Kit |
|---|---|---|
| Where it lives | Built into Copilot Studio UI | Separate Power CAT solution |
| Primary purpose | Behavioral validation | Functional verification |
| Setup effort | Minimal | Higher (Dataverse, AI Builder, App Insights optional) |
| Test creation | Manual, import, AI‑generated | Manual + Excel bulk |
| AI‑assisted scoring | Yes (core feature) | Yes (Generative Answers via AI Builder) |
| Deterministic checks | Limited | Strong (exact match, topic, attachments) |
| Multi‑turn scenarios | Not explicitly documented | Explicitly supported |
| Orchestration plan validation | Not documented | Explicitly supported |
| CI/CD & quality gates | Implicit / API‑based | Explicit pipeline integration |
| Governance & compliance | Not in scope | First‑class feature |
How they relate (this is the key insight)
Microsoft is not replacing the Copilot Studio Kit with Agent Evaluation. Instead, the sources show a clear layering strategy:
-
Agent Evaluation → Fast, AI‑assisted, in‑product validation → Ideal for early feedback, iteration, and continuous confidence
-
Copilot Studio Kit → Deep, deterministic, automatable verification → Ideal for release gates, regression testing, orchestration correctness, and governance
This positioning is also explicitly reflected in community and Microsoft guidance that frames Agent Evaluation as filling the gap that manual testing cannot scale, while the Kit remains the system‑level quality backbone.
Practical takeaway for enterprise teams
Based on what is explicitly documented:
When to use each tool
Agent Evaluation is best suited for:
- Rapid iteration cycles during agent development
- Early-stage quality validation before formal review
- Continuous behavioral checks without infrastructure complexity
- Scenarios where AI-assisted, semantic evaluation is sufficient
- Teams prioritizing speed of feedback over deterministic guarantees
- Questions like: “Is this agent generally behaving well after my last change?” → Use Agent Evaluation.
Copilot Studio Kit is best suited for:
- Production release gates and formal deployment approval
- Regression testing before pushing updates to production
- Regulatory and compliance-driven scenarios requiring audit trails
- Mission-critical agents where deterministic verification is mandatory
- Complex orchestration scenarios requiring plan and tool invocation validation
- Multi-turn conversations that need end-to-end correctness
- Questions like: “Did we break anything? Are the topics correct? Are the tools invoked? Can this ship?” → Use the Copilot Studio Kit.
How they complement each other
In mature setups, the tools are complementary, not competitive:
- Development phase: Agent Evaluation provides fast feedback loops for iteration
- Pre-production phase: Copilot Studio Kit enforces deterministic verification gates
- Production phase: Both tools support continuous monitoring—Agent Evaluation for behavioral trends, the Kit for functional regression detection
- Governance phase: The Kit’s compliance and KPI tracking provide the enterprise audit trail and policy enforcement layer
Organizations scaling from single-agent projects to enterprise deployments should expect to adopt both tools at different maturity stages, using them in sequence rather than as either/or choices.
Conclusion
Agent Evaluation and the Copilot Studio Kit represent Microsoft’s thoughtful answer to the agent testing maturity curve. As organizations build, iterate, and scale agents from proof-of-concept to mission-critical systems, both tools play essential roles at different stages of the lifecycle.
Agent Evaluation brings quality validation into the authoring experience, reducing friction in everyday iteration and making behavioral confidence accessible to all agent makers. Its AI-assisted approach acknowledges the reality of rapid development cycles and the need for fast feedback loops.
The Copilot Studio Kit, by contrast, provides the deterministic backbone that enterprises require—exact verification, governance enforcement, regulatory compliance, and the audit trails necessary for mission-critical deployments.
The key insight is that these tools are not competitors but complementary. Teams should adopt them in sequence, starting with Agent Evaluation during development for rapid iteration, then layering in the Copilot Studio Kit as the agent approaches production. Organizations serious about agent quality at scale will ultimately adopt both, using them to build confidence at every stage from ideation to production and beyond.



{kind=link}
Start the conversation